
一、云原生基础
1.1 云计算的历史
1.1.1 虚拟化技术起步时代
云计算的历史事实上需要追溯到60多年前的计算机远古历史:

1955年,John McCarthy(备注:John McCarthy是Artificial Intelligence/人工智能一词的提出者)创造了一种在用户群中共享计算时间的理论。
1959年6月,在国际信息处理大会上克里斯托弗Christopher Strachey发表了《Time Sharing in Large Fast Computer》论文,提出了虚拟化概念。该文被公认为虚拟化技术的最早论述。
1965年8月,IBM推出System/360 Model 67 和 TSS 分时共享系统(Time Sharing System),通过虚拟机监视器(Virtual Machine Monitor)虚拟所有的硬件接口,允许多个用户共享同一高性能计算设备的使用时间,也就是最原始的虚拟机技术。
在20世纪60年代中期,美国计算机科学家 JCR Licklider 提出计算机互联系统(an interconnected system of computers)的想法。
1969年,在 JCR Licklider 的革命性创意的帮助下,Bob Taylor 和 Larry Roberts 开发了互联网的前身 ARPANET(Advanced Research Projects Agency Network),允许不同物理位置的计算机进行网络连接和资源共享。
1972年,IBM发布了名为VM(Virtual Machine)的操作系统。在90年代,虚拟机的使用开始流行
1974年,Popek和Goldberg发表了《Formal Requirements for Virtualizable Third Generation Architectures》提出了虚拟化准备的充分条件,指出满足条件的控制程序可以被称为虚拟机监视器Virtual Machine Monitor (VMM):(1)一致性:一个运行于虚拟机上的程序,其行为应当与直接运行于物理机上的行为基本一致,只允许有细微的差异如系统时间方面;(2)可控性:VMM对系统资源有完全的控制能力和管理权限;(3)高效性:绝大部分的虚拟机指令应当由硬件直接执行而无需VMM的参与。
1978年,IBM获得了独立磁盘冗余阵列(Redundant Arrays of Independent Disks,RAID)概念的专利。该专利将物理设备组合为池,然后从池中切出一组逻辑单元号(Logical Unit Number,LUN)并将其提供给主机使用。虽然该技术直到1988年IBM才与加利福尼亚州立大学伯克利分校联合开发了第一个实用版本,但该专利第1次将虚拟化技术引入存储之中。
“Time-Sharing”的背景:自20世纪50年代,人类使用大型计算机系统来处理数据。而在早期,大型计算机体积庞大而且价格高昂。为了提高投资回报率,购买大型机的组织开始实施“分时调度(time-sharing)”,然后从没有处理能力的终端访问大型计算机。“分时”理论可以充分利用可用的计算时间,可以用于为无力购买自己的大型机的小公司提供计算时间。
这里便陆续出现了云计算的基本前提:共享计算能力和共享网络,并出现了虚拟机,虚拟网络和早期基础设施。
但是在2000年前后虚拟化技术成熟之前,市场处于物理机时代。当时如果要启用一个新的应用,需要购买一台或者一个机架的新服务器。
1.1.2 虚拟化技术成熟时代
在2000年前后,虚拟化技术逐渐发展成熟:
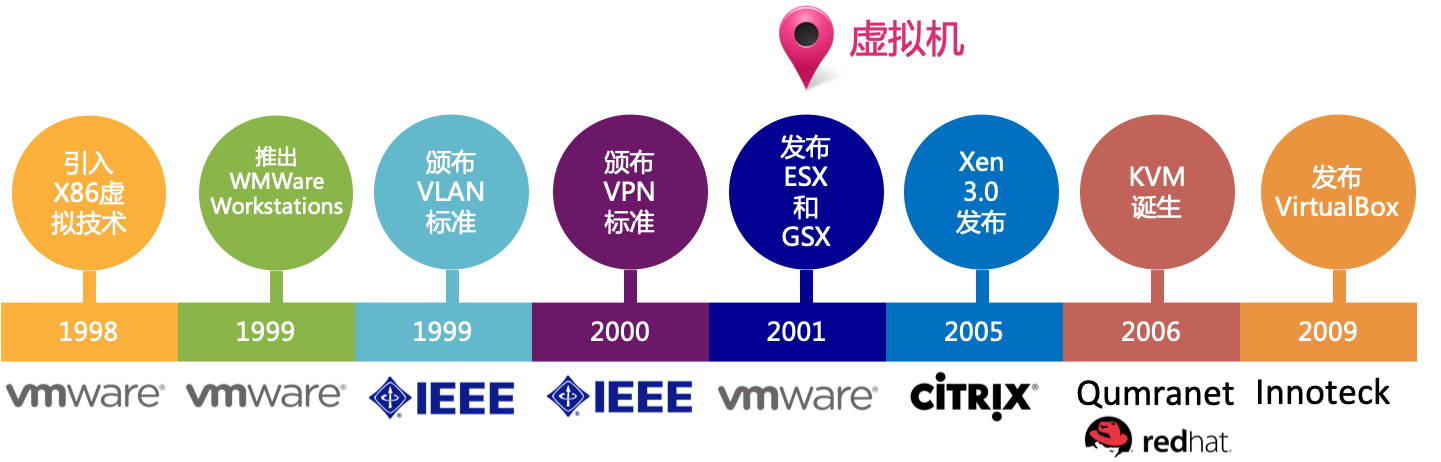
1998年,VMware成立并首次引入X86的虚拟技术,通过运行在Windows NT上的VMware来启动Windows 95。
1999年,VMWare推出可在X86平台上流畅运行的第一款VMware Workstation,从此虚拟化技术终于走下了大型机的神话。之后,研发人员和发烧友开始在普通PC和工作站上大量使用该虚拟化解决方案。
1999年,IEEE颁布了用以标准化VLAN实现方案的802.1Q协议标准草案,从而可以将大型网络划分为多个小网络,使得广播和组播流量不会占据更多带宽的问题;同时,可以利用VLAN标签提供更高的网络段间的安全性。
2000年,IEEE颁布了虚拟专用网(Virtual Private Network)VPN标准草案,从而使得私有网络可以跨公网进行建立。
2000年,Citrix桌面虚拟化产品正式发布。
2001年,VMware发布了第一个针对x86服务器的虚拟化产品ESX和GSX,即ESX-i的前身。
2003年10月,Xen虚拟化项目首次面世推出了1.0版本,此时仅支持半虚拟化Para-Virtualization。之后,基于Xen虚拟化解决方案陆续被Redhat、Novell和Sun等的Linux发行版集成,作为默认的虚拟化解决方案。
2003年,Microsoft收购Connectix获得虚拟化技术进入桌面虚拟化领域,之后很快推出了Virtual Server免费版。
2005年,Xen 3.0发布,该版本可以在32位服务器上运行,同时该版本开始正式支持Intel的VT技术和IA64架构,从而使得Xen虚拟机可以运行完全没有修改的操作系统。该版本是Xen真正意义上可用的版本。
2006年10月,以色列的创业公司Qumranet在完成了虚拟化Hypervisor基本功能、动态迁移以及主要的性能优化之后,正式对外宣布了KVM的诞生。同年10月,KVM模块的源代码被正式接纳进入Linux Kernel,成为内核源代码的一部分。备注:Qumranet在2008年被RedHat收购。
2009年4月,VMware推出业界首款云操作系统VMware vSphere。
云计算的重要里程碑之一是2001年VMWare带来的可用于X86的虚拟化计划。通过虚拟机,可以在同一台物理机器上运行多个虚拟机,这意味着可以降低服务器的数量,而且速度和弹性也远超物理机。
1.1.3 基于虚拟机的云计算时代
在虚拟化技术成熟之后,云计算市场才真正出现,此时基于虚拟机技术诞生了众多的云计算产品,也陆续出现了IaaS、PaaS等平台和公有云、私有云、混合云等形态:

2006年,AWS推出首批云产品Simple Storage Service (S3)和Elastic Compute Cloud(EC2),使企业可以利用AWS的基础设施构建自己的应用程序
2008年4月,Google App Engine发布,是 Google 管理的数据中心中用于 WEB 应用程序的开发和托管的平台。
2009年,Heroku 推出第一款公有云 PaaS (Platform-as-a-Service)
2010年1月,微软发布 Microsoft Azure云平台服务。备注:Microsoft Azure 于2008年宣布。
2010年7月,Rackspace Hosting和NASA联合推出了一项名为OpenStack的开源云软件计划
2011年,Pivotal推出了开源版PaaS Cloud Foundry,作为Heroku PaaS的开源替代品,并于2014年底推出了Cloud Foundry Foundation。
2013年底,Google 推出 Google Compute Engine (GCE)正式版。备注:GCE的测试版本于2008年发布,预览版于2012年发布。
2014年,AWS推出 Lambda,允许在AWS中运行代码而无需配置或管理服务器,即Faas/Serverless。
在这期间,出现了云计算的多个重要里程碑:
IaaS的出现:通过按时计费的方式租借服务器,将资本支出(Capex)转变为运营支出(Opex),这使得云计算得以大规模兴起和普及。
Capex Vs. Opex:
Capex = capital expenditure / 资本支出
Opex = operational expenditure / 运营支出
PaaS的出现
开源IaaS的出现:云计算已经开始进入开源时代
开源PaaS的出现
FaaS的出现
IaaS(Infrastructure as a Service,基础设施即服务):IaaS是一种云计算服务模型,它提供了虚拟化的计算资源,如虚拟机、存储和网络,让用户能够创建和管理自己的基础设施,包括操作系统、应用程序等。用户负责管理操作系统、应用程序和相关的补丁更新。例如阿里云ECS、OSS、SLB、RDS等都属于IaaS。有了IaaS,客户不用关注物理机器。
PaaS(Platform as a Service,平台即服务): PaaS是一种更高级别的云服务模型,它不仅提供基础设施,还包括应用程序开发和部署所需的平台环境。PaaS提供了开发、测试、部署和扩展应用程序的工具和环境,使开发人员可以集中精力在应用程序逻辑上,而不必担心底层基础设施。例如阿里云容器服务、消息队列、API网关等都属于PaaS。有了PaaS,客户不用关注操作系统。
SaaS(Software as a Service,软件即服务): SaaS是一种在云端交付应用程序的模型,用户可以通过网络访问应用程序,而无需在本地安装或维护。所有的软件和数据都托管在云端,提供商负责管理和维护应用程序及其基础设施。用户只需要通过浏览器或移动应用来使用软件。例如企业微信在线文档、Tapd等都属于SaaS。有了SaaS,客户不用关注应用程序。
FaaS(Function as a Service,函数即服务): FaaS是一种计算模型,它允许开发人员以事件驱动的方式执行代码函数。开发人员只需上传其代码功能,当特定事件触发时,云提供商会自动扩展和执行这些功能,用户只支付实际使用的计算资源。例如阿里云云函数计算、AWS Lambda属于FaaS。有了FaaS,客户只需关注通用业务功能。
Serverless(无服务器): Serverless不是严格意义上的一个服务模型,而是一种计算范式。它建立在FaaS模型之上,强调开发人员无需关心服务器的管理和维护。在Serverless中,开发者将重点放在编写和部署功能代码上,而云提供商负责管理底层基础设施的弹性扩展、负载平衡等。尽管名为"Serverless",但实际上底层仍然使用服务器,只是开发者不再需要显式管理它们。Serverless更加抽象,FaaS是其实现方式之一。

1.1.4 容器化时代
2013年,在云计算领域发生了一件影响深广的技术变革:容器。
容器技术可以说是过去十年间对软件开发行业改变最大的技术,而从虚拟机到容器,整个云计算市场发生了一次重大变革,甚至是洗牌。基于容器技术的容器编排市场,则经历了Mesos、Swarm、kubernetes三家的一场史诗大战,最终以kubernetes全面胜利而告终:
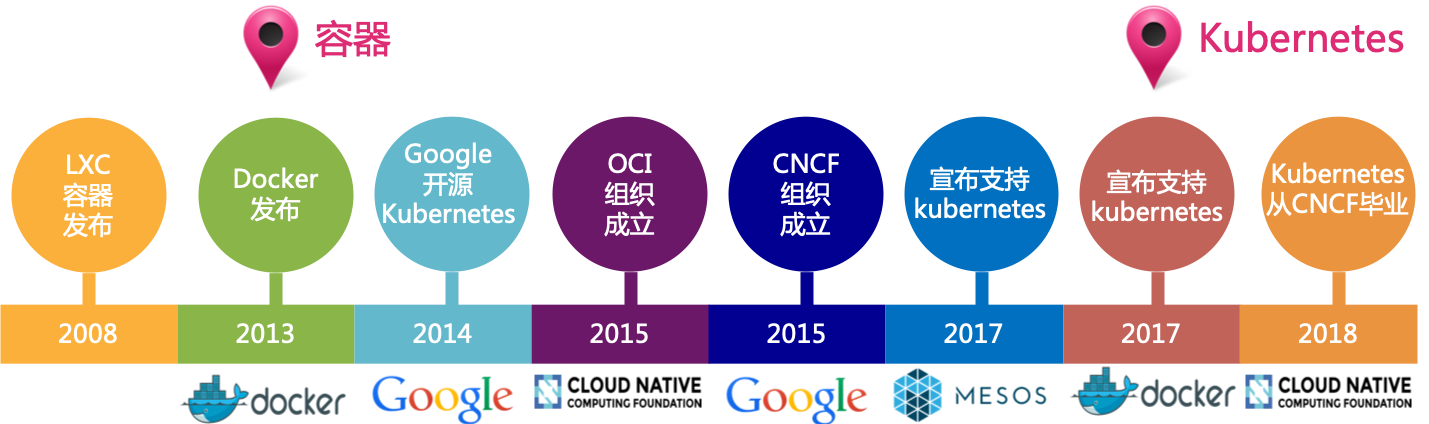
2008年,LXC(Linux Container)容器发布,这是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源。LXC是Docker最初使用的具体内核功能实现
2013年,Docker发布,组合LXC,Union File System和cgroups等Linux技术创建容器化标准,docker风靡一时,container逐步替代VM,云计算进入容器时代
2014年底,CoreOS正式发布了CoreOS的开源容器引擎Rocket(简称rkt)
2014年10月,Google 开源 kubernetes,并在2015年捐赠给 CNCF
2015年6月,OCI组织成立,旨在制定并维护容器镜像格式和容器运行时的正式规范,以便在不同的操作系统和平台之间移植
2015年7月,Google联合Linux基金会成立了CNCF组织,kubernetes 成为 CNCF 管理的首个开源项目
2015年,CNCF组织开始力推 Cloud Nativ ,完全基于开源软件技术栈,Cloud Native 的重要理念是:以微服务的方式部署应用,每个应用都打包为自己的容器并动态编排这些容器以优化资源利用
2017年9月,Mesos宣布了对Kubernetes的支持
2017年10月,Docker宣布将在下一版Docker,将同时支持自家调度引擎Swarm和来自Google的调度平台Kubernetes
2018年3月,Kubernetes 从 CNCF 毕业,成为 CNCF 第一个毕业项目
这里有两个重要的里程碑:
2013年,Docker发布,容器逐步替代VM,云计算进入容器时代
2017年底,Kubernetes 赢得容器编排的胜利,云计算进入 Kubernetes 时代
在容器编排大战期间,以 kubernetes 为核心的CNCF Cloud Native生态系统也得以迅猛发展,云原生成为云计算市场的技术新热点。
1.2 云原生的定义
1.2.1 一句话概述云原生
百度百科:云原生是基于分布部署和统一运管的分布式云 ,以容器、微服务、DevOps等技术为基础建立的一套云技术产品体系。
Google:云原生是指构建和运行应用以充分利用通过云交付模式交付的分布式计算。
维基百科:是一种由软件实现的功能或应用程序,与运行在物理设备上的传统网络不同,它是运行在Linux容器内的,通常由Kubernetes编排 。
AWS:云原生是在云计算环境中构建、部署和管理现代应用程序的软件方法。
OpenApi:云原生是一种现代化的软件开发和部署方法,旨在实现高度可扩展、灵活性和稳定性,利用云计算和容器化技术来构建、交付和运行应用程序。
1.2.2 云原生概念演变
云原生意味着应用程序原生就被设计为在云上以最佳方式运行。
云原生是一种专门针对云上应用而设计的方法,用于构建和部署应用,以充分发挥云计算的优势。这些应用的特点是可以实现快速和频繁的构建、发布、部署,结合云计算的特点实现和底层硬件和操作系统解耦,可以方便的满足在扩展性,可用性,可移植性等方面的要求,并提供更好的经济性。同时通过拆解为多个小型功能团队来让组织更敏捷,让人员、流程和工具更好的结合,在开发、测试、运维之间进行更密切的协作。
但是当需要回答“什么是云原生”这个问题时,还是会有些困难:在过去几年间,云原生的定义一直在变化和发展演进,不同时期不同的公司对此的理解和诠释也不尽相同,因此往往会带来一些疑惑和误解。
Pivotal的定义
Pivotal是Cloud Native/云原生应用的提出者,并推出了Pivotal Cloud Foundry和Spring系列开发框架,是云原生的先驱者和探路者。
2015年,来自Pivotal公司的Matt Stine编写了一本名为《迁移到云原生应用架构》的电子书,提出云原生应用架构应该具备的几个主要特征:
符合12因素应用(Twelve-Factor Applications)
面向微服务架构(Microservices)
自服务敏捷架构(Self-Service Agile Infrastructure)
基于API的协作(API-Based Collaboration)
抗脆弱性(Antifragility)
在2017年10月,也是Matt Stine,在接受InfoQ采访时,则对云原生的定义做了小幅调整,将Cloud Native Architectures定义为具有以下六个特质:
模块化(Modularity):(通过微服务)
可观测性(Observability)
可部署性(Deployability)
可测试性(Testability)
可处理性(Disposability)
可替换性(Replaceability)
而在Pivotal最新的官方网站 https://pivotal.io/cloud-native 上,对cloud native的介绍则是关注如下图所示的四个要点:
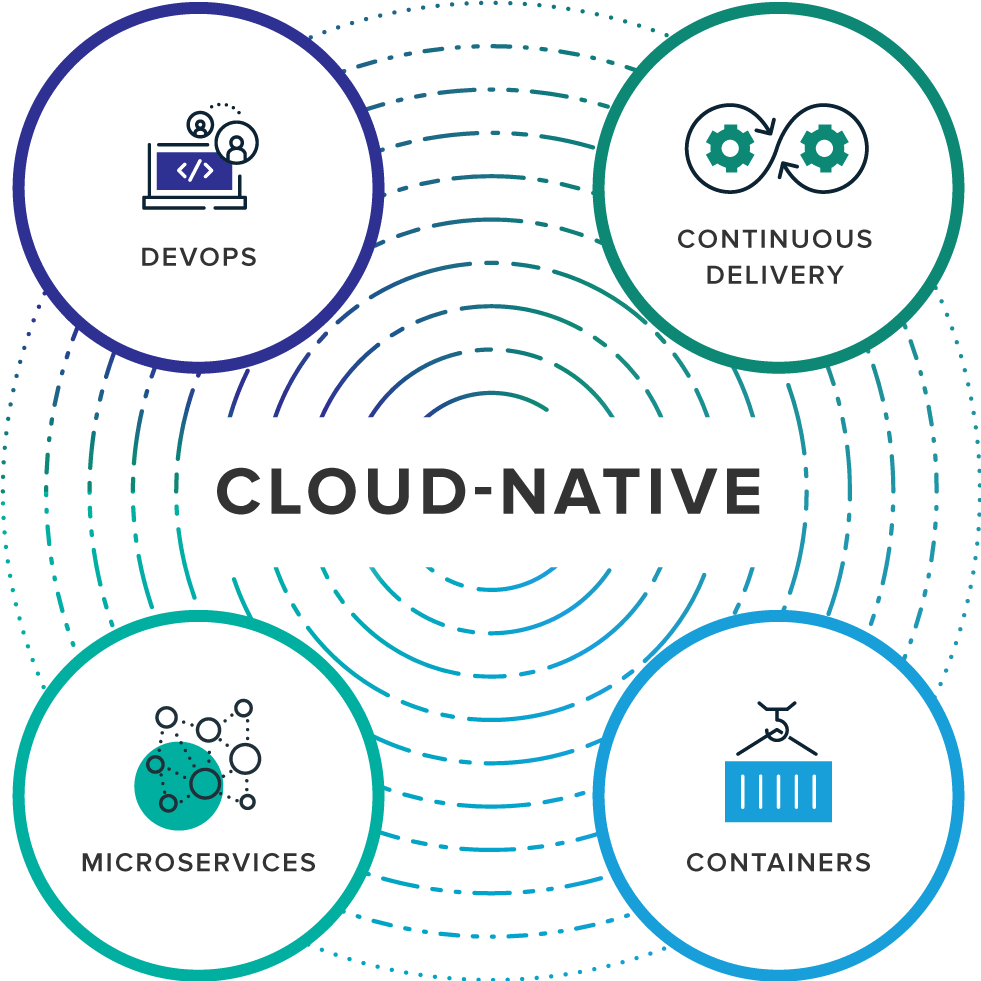
DevOps(开发&运维模式)
Continuous Delivery(持续交付)
Microservices(微服务)
Containers(容器化)
CNCF的定义
2015年CNCF(Cloud Native Computing Foundation,云原生计算基金会)建立,开始围绕云原生的概念打造云原生生态体系,起初CNCF对云原生的定义包含以下三个方面:
应用容器化(software stack to be Containerized)
面向微服务架构(Microservices oriented)
应用支持容器的编排调度(Dynamically Orchestrated)
云原生包含了一组应用的模式,用于帮助企业快速,持续,可靠,规模化地交付业务软件。云原生由微服务架构,DevOps 和以容器为代表的敏捷基础架构组成。
在2018年,随着社区对云原生理念的广泛认可和云原生生态的不断扩大,还有CNCF项目和会员的大量增加,起初的定义已经不再适用,因此CNCF对云原生进行了重新定位。
2018年6月,CNCF正式对外公布了更新之后的云原生的定义(包含中文版本)v1.0版本:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone.
云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。
新的定义中,继续保持原有的核心内容:容器和微服务,但是非常特别的将服务网格单独列出来,而不是将服务网格作为微服务的一个子项或者实现模式,体现了云原生中服务网格这一个新生技术的重要性。而不可变基础设施和声明式API这两个设计指导理念的加入,则强调了这两个概念对云原生架构的影响和对未来发展的指导作用。

个人对于云原生理解
从字面意思拆分开理解:“云(Cloud)”和“原生(Native)”。
“云(Cloud)”:这个“云”放在科技环境下由从指代网络、互联网的标识到现在的云计算,所以可以说“云”在现在我们默认指代云计算,而不是传统的数据中心。
“原生(Native)”:表示应用程序从设计之初即考虑到云的环境,原生为云而设计,在云上以最佳姿势运行,充分利用和发挥云平台的弹性+分布式优势。
所以"云原生"可以简单的理解为:“一个应用系统借助云计算相关的周边技术进行设计研发,从而使该应用能完美的适配云上环境”。
是一种快速构建应用的设计理念
必须建立在云计算的基础上
不单指一种技术,而是一种快速交付应用的技术集合
云原生定义之外
云原生的内容和具体形式随着时间的推移一直在变化,即便是CNCF最新推出的云原生定义也非常明确的标注为v1.0,相信未来我们很有机会看到v1.1、v2版本。而且云原生这个词汇最近被过度使用,混有各种营销色彩,容易发生偏离。因此,云原生的定义是什么并不重要,关键还是云原生定义后面的理念、文化、技术、工具、组织结构和行为方式。
Joe Beda,Heptio 的CTO,指出:
There is no hard and fast definition for what Cloud Native means. In fact there are other overlapping terms and ideologies. At its root, Cloud Native is structuring teams, culture and technology to utilize automation and architectures to manage complexity and unlock velocity.
Cloud Native并没有硬性和牢靠的定义。实际上,还有其他重叠的术语和意识形态。从根本上说,Cloud Native正在构建团队,文化和技术,以利用自动化和架构来管理复杂性和解锁速度。
We are still at the beginning of this journey.
我们还处在这个旅程的开始阶段。
Christian Posta 指出:
“Cloud native” is an adjective that describes the applications, architectures, platforms/infrastructure, and processes, that together make it economical to work in a way that allows us to improve our ability to quickly respond to change and reduce unpredictability. This includes things like services architectures, self-service infrastructure, automation, continuous integration/delivery pipelines, observability tools, freedom/responsibility to experiment, teams held to outcomes not output, etc.
“云原生”是一个形容词,用于描述应用,结构,平台/基础设施和流程,这些共同促使我们以比较经济的工作方式来提高能力,实现快速响应变化和减少不可预测性。包括服务架构,自助服务基础设施,自动化,持续集成/交付管道,可观察性工具,实验的自由/责任,坚持结果而不是产出的团队等。
1.2.3 云原生的目标
云原生的定义并没有那么重要,不要陷入到概念的死胡同,了解云原生的目标是有必要的:
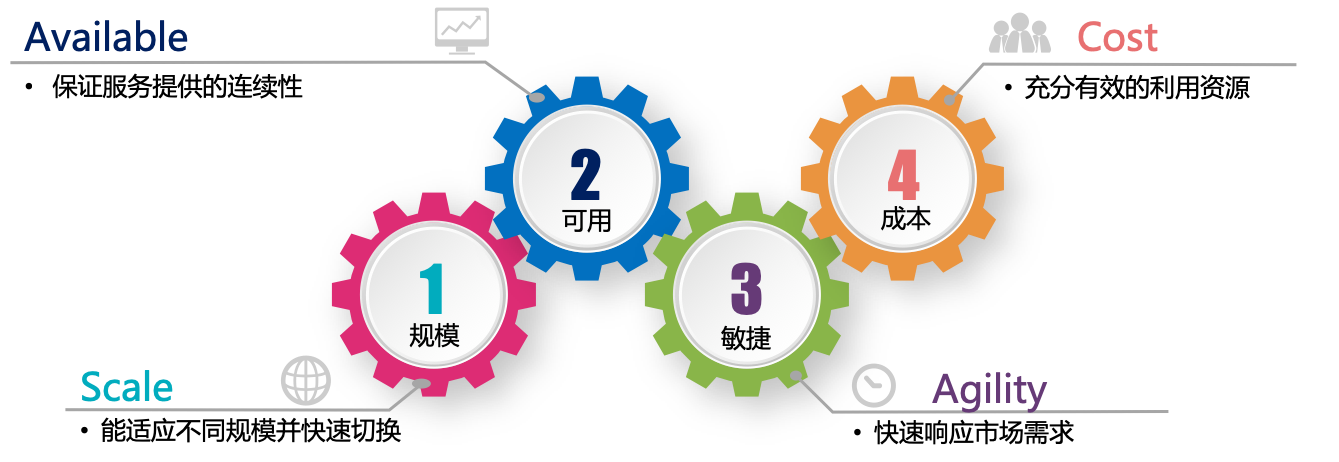
规模:要求云原生服务能够适应不同的规模(包括但不限于用户规模/部署规模/请求量),并能够在部署时动态分配资源,以便在不同的规模之间快速和平滑的伸缩。典型场景如:初创公司或新产品线快速成长,用户规模和应用部署规模在短时间内十倍百倍增长;促销、季节性、节假日带来的访问量波动,高峰时间段的突发流量等。
可用:通过各种机制来实现应用的高可用,以保证服务提供的连续性。
敏捷:快速响应市场需求
成本:充分有效的利用资源
在这四个核心目标之间,存在彼此冲突的情况:
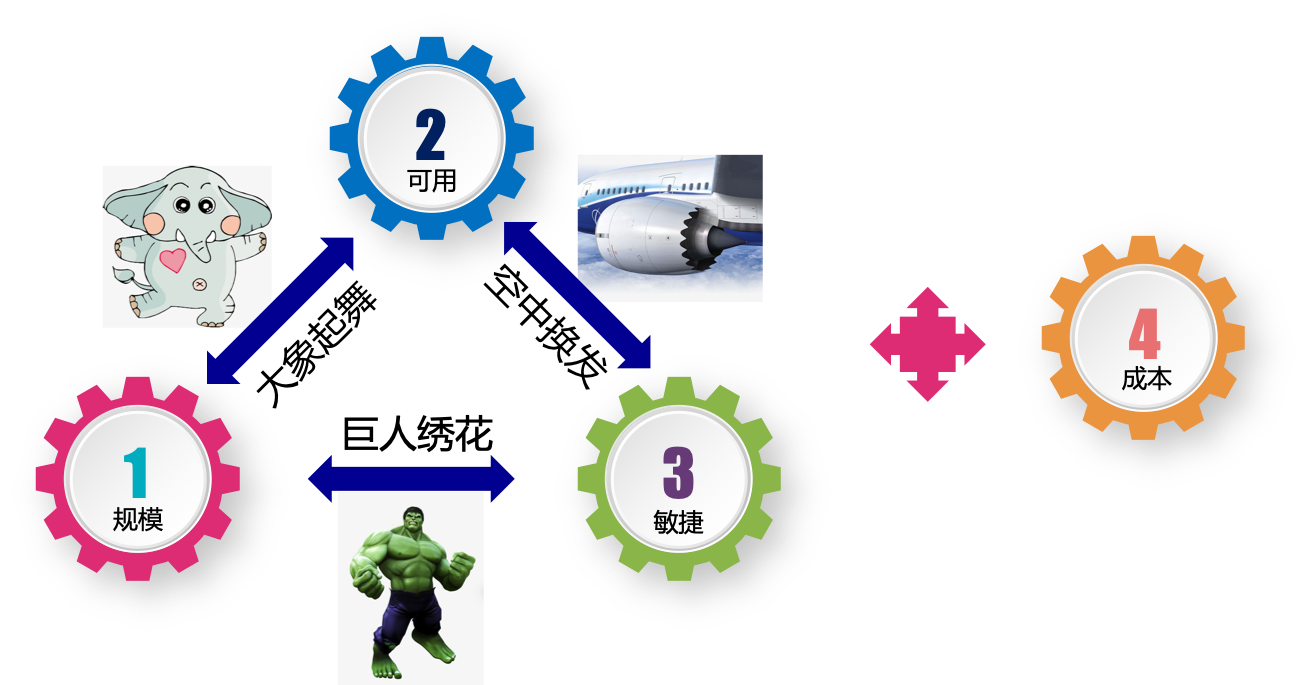
规模和敏捷之间的冲突:规模大而又要求敏捷,我们比喻为“巨人绣花”。
规模和可用性之间的冲突:规模大而要求可用性高,我们比喻为“大象起舞”。
敏捷和可用性之间的冲突:敏捷而要求高可用,我们比喻为“空中换发”。
而云原生应用,必须要在同时满足这三个目标的前提下,还要实现成本控制。要解决这个问题可以用飞轮效应来解决。
1.2.4 云计算的部署方式
并非所有云计算都是相同的,也并非一种云计算适合所有场景,主流的云计算部署方式分为三类:公有云、私有云、混合云。
公有云:公有云通常指第三方提供商提供给用户进行使用的云,公有云一般可通过互联网使用。阿里云、腾讯云和百度云等是公有云的应用示例,借助公有云,所有硬件、软件及其他支持基础架构均由云提供商拥有和管理
私有云:私有云是为一个客户单独使用而构建的云,因而提供对数据、安全性和服务质量的最有效的控制。使用私有云的公司拥有基础设施,并可以控制在此基础设施上部署应用程序的方式
混合云:混合云是公有云和私有云这两种部署方式的结合。由于安全和控制原因,企业中并非所有的信息都能放置在公有云上。因此,大部分已经应用云计算的企业将会使用混合云模式

二、云原生技术体系
2.1 微服务
微服务是一种架构设计风格,解决的是我们软件开发中一直追求的低耦合+高内聚,它将应用构建为一个小型自治服务的集合,以业务领域驱动为模型,把一个大型的单个应用程序和服务拆分为数个甚至数十个的支持微服务,它可扩展单个组件而不是整个的应用程序堆栈,从而满足服务等级协议。例如一个tomcat容器中部署一个超大型管理系统的场景,而微服务的本质是把一块大饼分成若干块低耦合的小饼,比如一块小饼专门负责接收外部的数据,一块小饼专门负责响应前台的操作,小饼可以进一步拆分,比如负责接收外部数据的小饼可以继续分成多块负责接收不同类型数据的小饼,这样每个小饼出问题了,其它小饼还能正常对外提供服务。
每个微服务器都可以独立于应用程序中的其他服务进行部署,升级,扩展和重新启动,通常作为自动化系统的一部分,可以在不影响终端客户使用的情况下频繁独立更新。
微服务还建议使用RESTfulAPI通信,且局限于某一门开发语言,而是在系统的不同层次上选择最适合的语言进行,流行的微服务开发语言有: Go、Java、NodeJS、Python等。针对于Java的一些关键技术:
微服务网关:推荐学习
Spring Cloud Gateway,作为微服务网关,可实现统一鉴权、服务监控、负载、服务限流、日志记录等等功能。限流降级:推荐搭配
Sentinel + Sentinel Dashboard,Sentinel 是 Spring Cloud Alibaba的组件,可实现服务熔断、限流、降级以及热点防护等功能,Sentinel Dashboard 为 Sentinel 提供可视化Web控制台。Sentinel 的同类产品还有Hystrix、Resilience 4J,但不建议使用Hystrix,因为已经停止维护了。服务调用:推荐学习
Dubbo Spring Cloud,因为Dubbo的传输性能,对比只基于http的 OpenFeign 要高的多。分布式事务:推荐学习Alibaba的
Seata框架,它提供了AT、TCC、SAGA 和 XA 事务模式,基本能应付大多数的应用场景。健康监控:如果条件允许,推荐搭配
Spring Boot Actuator + Prometheus + Grafana。Spring Boot Actuator 帮我们实现了对程序内部运行情况监控,比如监控状况、Bean加载情况、环境变量、日志信息、线程信息等;Prometheus是一套开源的系统监控和报警框架;Grafana 可以通过将采集的数据查询然后可视化地展示,并及时通知。Actuator 提供端点将数据暴露出来, Prometheus 定时去拉取数据并保存和提供搜索和展示, Grafana 提供更加精美的图像化展示。如果想简单监控,可以搭配Spring Boot Actuator + Spring Boot Admin,Admin提供可视化展示页面。注册中心:推荐学习Alibaba的
Nacos。同类产品还有Eureka、Zookeeper、Consul等,Eureka在分布式事务上支持AP的,后两者支持CP,而Nacos可自动切换是AP还是CP。配置中心:推荐学习Alibaba的
Nacos。同类产品还有 Spring Cloud Config、Apollo(携程),但它们在功能完善度和使用简单性上,不如Nacos。链路追踪:推荐搭配
Spring Cloud Sleuth + Zipkin,Zipkin的同类产品还有Cat、Pinpoint、SkyWalking等。选择 Zipkin 的原因是因为简单好上手,如果有条件,可以尝试其他产品。Java诊断工具:推荐学习Alibaba的
Arthas,以往排除线上Java问题时需要用到 jps、jmap、jstack 等jdk工具,Arthas可以完美替代这些。消息中间件:消息中间件推荐
RabbitMQ,同类产品还有Kafka、RocketMQ,实际上RabbitMQ在三者中并发吞吐量是最差的,但它的优点在于对数据的一致性、稳定性和可靠性有更好的保障。在to B的业务开发中,RabbitMQ更适合。缓存数据库:分布式缓存推荐使用
Redis,本地缓存可以试试 EhCache框架。分布式协调:推荐学习
ZooKeeper,它的选举、监听等机制,为分布式协调提供了很好的支持,例如分布式锁。定时调度:推荐使用
xxl-job,同类型产品还有quartz、elastic-job等。综合考虑架构设计、学习成本等因素,xxl-job更为适合。搜索引擎:推荐学习
Elastic Search,这没得说,Elastic Search是当前最流行的搜索引擎。MySQL增量同步:推荐学习Alibaba的
Canal,它可以实现以MySQL为数据源的增量同步。
微服务设计拆分是架构设计中的难点,要将服务拆分合理并不容易。
2.2 容器化
容器化是一种软件部署流程,可将应用程序的代码与应用程序在任何基础设施上运行所需的所有文件和库进行捆绑。通常,要在计算机上运行任何应用程序,必须安装与计算机操作系统匹配的应用程序版本。例如,您需要在 Windows 计算机上安装 Windows 版本的软件包。但是借助容器化,您可以创建能够在所有类型的设备和操作系统上运行的单个软件包或容器。
容器比虚拟机(VM)提供了更高的效率和更快的速度。使用操作系统(OS)级别的虚拟化,单个操作系统实例被动态划分为多个相互独立的容器,每个容器具有唯一可写的文件系统和资源配额。创建和销毁容器的低开销,以及单个instance可高密度运行多个容器的特性使得容器成为部署微服务各个模块的完美工具。

容器化的好处在于,运维的时候不需要再关心每个服务所使用的技术栈了,每个服务都被无差别地封装在容器里,可以被无差别地管理和维护,现在比较流行的工具是docker和k8s。
2.2.1 Docker
Docker 无疑是最常用的容器平台。 该平台不仅是免费的,而且还是开放源代码的,并且可以在所有主要的 Linux 分发版以及 Windows Server 2016 上运行。 2015 年,Docker 向开放容器计划 (OCI) 捐赠了容器映像规范和运行时代码,以帮助规范和发展容器生态系统。 2017 年,Docker 向 Cloud Native Computing Foundation (CNCF) 捐赠了行业标准的容器运行时。 该运行时的创建重点在于简单性、可靠性和可移植性。
Docker的主要目标是“ Build, Ship[ and Run Any App,Anywhere ",也就是通过对应用组件的封装、分发、部署、运行等生命期的管理,使用户的APP (可以是一个WEB应用或数据库应用等等)及其运行环境能够做到“一次封装,到处运行“。
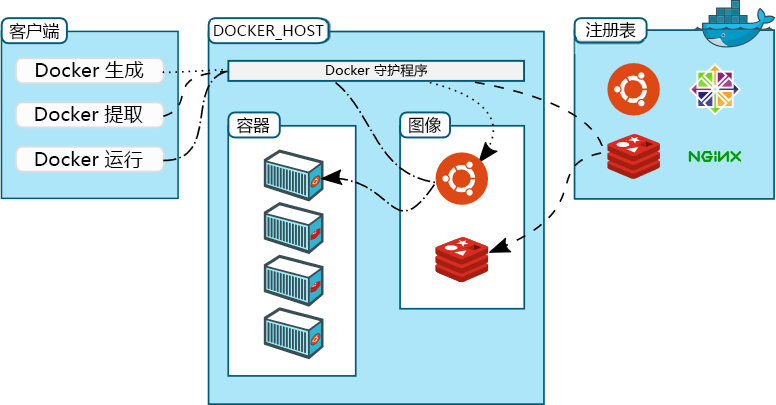
上图显示了一种可在 Docker 容器中运行应用程序的系统体系结构。 图中首先展示 Docker 客户端工具,该工具用于创建、运行和管理容器和容器映像。 (容器映像构成运行的容器的蓝图,而 VM 映像定义加载到运行的 VM 中的内容。)存在各种 Docker 客户端,包括 Docker 自己的命令行接口(可在所有常用的操作系统上运行)和 Kitematic(具有图形用户界面并可在 Windows 和 macOS 上运行)。 Docker 于 2015 年收购了 Kitematic,并使其成为 Docker Toolbox 的一部分,可供免费使用。
容器映像构建完毕之后将被上传到容器注册表中的存储库。 容器注册表的目的是存储容器映像,使其可供公开或私下使用。 Docker 提供了自己的基于云的容器注册表(称为“Docker Hub”),可为用户提供无限的免费公用存储库和一个免费的专用存储库。 它还允许(甚至鼓励)其他人创建自己的注册表,并提供开放源代码 Docker 注册表来帮助他们的工作。 这就是 Amazon、Microsoft 和 Google 等主要云服务提供商能够在其云平台中提供 Docker 兼容的注册表的原因之一。
通过使用 Docker 客户端向 Docker 守护程序发出命令并指定应从哪个映像创建容器来启动容器。 (守护程序是在主机的后台运行的程序。)然后,守护程序会创建一个容器并将该映像加载到其中。 运行后,可以通过从 Docker 客户端发出命令来启动和停止容器。 Docker 客户端和 Docker 守护程序不必位于同一计算机上。 在典型方案中,客户端在一台计算机上运行,而守护程序在远程服务器上运行,并且客户端使用安全外壳 (SSH) 协议将命令传输到守护程序。
更快速的应用交付和部署:传统的应用开发完成后,需要提供一堆安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间。
更便捷的升级和扩缩容:随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成-块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。
更简单的系统运维:应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度–致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。
更高效的计算资源利用:Docker是内核级虚拟化 ,其不像传统的虚拟化技术一样 需要额外的Hypervisor支持,所以在-台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率。
2.2.2 K8S
GitHub:https://github.com/kubernetes/kubernetes
K8S的全称为 Kubernetes。用于自动部署、扩展和管理“容器化(containerized)应用程序”的开源系统。
K8S是负责自动化运维管理多个容器化程序(比如 Docker)的集群,是一个生态极其丰富的容器编排框架工具。
K8S是Google开源的容器集群管理系统,在Docker等容器技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列功能,提高大规模容器集群管理的便捷性。
K8S由google的Borg系统(博格系统,google内部使用的大规模容器编排工具)作为原型,后经GO语言延用Borg的思路重写并捐献给CNCF基金会开源。云原生基金会(CNCF)于2015年12月成立,隶属于Linux基金会。CNCF孵化的第一个项目就是Kubernetes,随着容器的广泛使用,Kubernetes已经成为容器编排工具的事实标准。
Kubernetes的发展

传统部署时代: 早期,组织在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这导致了资源分配问题。例如,如果多个应用程序在一台物理服务器上运行,则可能会出现一个应用程序占用大部分资源的情况,从而导致其他应用程序表现不佳。解决方案是在不同的物理服务器上运行每个应用程序。但由于资源未得到充分利用,这种情况无法扩展,而且组织维护许多物理服务器的成本很高。
虚拟化部署时代:作为一种解决方案,虚拟化被引入。它允许您在单个物理服务器的 CPU 上运行多个虚拟机 (VM)。虚拟化允许应用程序在虚拟机之间隔离,并提供一定程度的安全性,因为一个应用程序的信息不能被另一个应用程序自由访问。
虚拟化可以更好地利用物理服务器中的资源,并实现更好的可扩展性,因为可以轻松添加或更新应用程序,降低硬件成本等等。通过虚拟化,您可以将一组物理资源呈现为一次性虚拟机集群。
每个虚拟机都是一台完整的机器,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:容器与虚拟机类似,但具有宽松的隔离属性,可以在应用程序之间共享操作系统(OS)。因此,容器被认为是轻量级的。与虚拟机类似,容器有自己的文件系统、CPU 共享、内存、进程空间等。由于它们与底层基础设施分离,因此可以跨云和操作系统发行版移植。
Kubernetes可以做什么?
服务发现和负载平衡 Kubernetes 可以使用 DNS 名称或使用自己的 IP 地址公开容器。如果容器的流量很高,Kubernetes 能够进行负载均衡并分配网络流量,从而使部署稳定。
存储编排 Kubernetes 允许您自动挂载您选择的存储系统,例如本地存储、公共云提供商等。
自动推出和回滚 您可以使用 Kubernetes 描述已部署容器的所需状态,并且它可以以受控的速率将实际状态更改为所需状态。例如,您可以自动化 Kubernetes 来为您的部署创建新容器、删除现有容器并将其所有资源采用到新容器。
自动装箱 您为 Kubernetes 提供了一个节点集群,可用于运行容器化任务。您告诉 Kubernetes 每个容器需要多少 CPU 和内存 (RAM)。Kubernetes 可以将容器安装到您的节点上,以充分利用您的资源。
自我修复 Kubernetes 会重新启动发生故障的容器、替换容器、终止不响应用户定义的运行状况检查的容器,并且在准备好提供服务之前不会将它们通告给客户端。
秘密和配置管理 Kubernetes 允许您存储和管理敏感信息,例如密码、OAuth 令牌和 SSH 密钥。您可以部署和更新机密和应用程序配置,而无需重建容器映像,也无需在堆栈配置中公开机密。
Kubernetes的核心组件

控制平面组件:控制平面组件会为集群做出全局决策(如:集群资源调度、检测和响应等),控制节点可以在集群中的任何节点上运行。包含kube-apiserver、etcd、kube-scheduler、kube-controller-manager、cloud-controller-manager。
Node组件:是Kubernetes中的工作节点,最开始被称为minion。一个Node可以是VM或物理机。每个Node(节点)具有运行pod的一些必要服务,并由Master组件进行管理,Node节点上包含kubelet、kube-proxy、Container Runtine。
Kubernetes和Docker的区别
抽象层次不同:Docker提供了一种容器化的技术,而Kubernetes提供了一个容器编排和管理的平台。Docker更关注如何构建和打包容器,而Kubernetes更关注如何在集群上管理和运行这些容器。
管理范围不同:Docker主要用于本地开发和单主机环境中的容器管理,而Kubernetes适用于多主机或云环境中的容器编排和调度。
功能不同:Docker提供了基本的容器操作,如启动、停止和删除容器。而Kubernetes提供了更高级和复杂的功能,如自动伸缩、负载均衡和服务发现。
应用程序生命周期管理:Kubernetes更关注整个应用程序的生命周期管理,包括部署、自动扩展、更新和回滚。而Docker更注重容器本身的构建和管理。
缩放能力:Kubernetes提供了自动伸缩功能,可以根据应用程序的负载情况自动调整容器的数量。Docker只能手动进行缩放操作。
高可用性:Kubernetes提供了高可用性的能力,可以在集群中的不同节点上运行容器,并根据需要重新启动或迁移容器。Docker只能在单个主机上运行容器。
2.3 声明式API
什么是Declarative?
Declarative(声明式设计)指的是这么一种软件设计理念和做法:我们向一个工具描述我们想要让一个事物达到的目标状态,由这个工具自己内部去figure out如何令这个事物达到目标状态。
和Declarative(声明式设计)相对的是Imperative或Procedural(过程式设计)。两者的区别是:在Declarative中,我们描述的是目标状态(Goal State),而在Imperative模式中,我们描述的是一系列的动作。这一系列的动作如果被正确的顺利执行,最终结果是这个事物达到了我们期望的目标状态的。
我们最常接触的其实是命令式编程,它要求我们描述为了达到某一个效果或者目标所需要完成的指令,常见的编程语言 Go、Ruby、C++ 其实都为开发者了命令式的编程方法。
SQL 其实就是一种常见的声明式『编程语言』,它能够让开发者自己去指定想要的数据是什么。或者说,告诉数据库想要的结果是什么,数据库会帮我们设计获取这个结果集的执行路径,并返回结果集。众所周知,使用 SQL 语言获取数据,要比自行编写处理过程去获取数据容易的多。
声明式和命令式是两种截然不同的编程方式:
在命令式 API 中,我们可以直接发出服务器要执行的命令,例如: “运行容器”、“停止容器”等;
在声明式 API 中,我们声明系统要执行的操作,系统将不断向该状态驱动。
K8S中的声明式
Kubernetes 中的 YAML 文件也有着相同的原理,我们可以告诉 Kubernetes 想要的最终状态是什么,而它会帮助我们从现有的状态进行迁移。
如果 Kubernetes 采用命令式编程的方式提供接口,那么工程师可能就需要通过代码告诉 Kubernetes 要达到某个状态需要通过哪些操作,相比于更关注状态和结果声明式的编程方式,命令式的编程方式更强调过程。

总而言之,Kubernetes 中声明式的 API 其实指定的是集群期望的运行状态,所以在出现任何不一致问题时,它本身都可以通过指定的 YAML 文件对线上集群进行状态的迁移,就像一个水平触发的系统,哪怕系统错过了相应的事件,最终也会根据当前的状态自动做出做合适的操作。
2.4 不可变基础设施
不可变基础设施是云原生架构中的一个重要概念,它强调在应用程序和基础设施的开发、部署和维护过程中,采用不可变的原则,以提高系统的可靠性、安全性和可维护性。在不可变基础设施的理念下,一旦基础设施被创建或配置,就不应该被直接修改,而是通过替换来进行更新或修复。
例如以下的实际例子就是不可变基础设施:
容器化集群: 使用容器编排工具如Kubernetes来管理应用程序的容器,每次更新应用程序时,可以通过创建新的容器镜像来替代旧的镜像,从而实现不可变性。整个应用程序环境在每次部署时都是一致的,可以轻松扩展、回滚和管理。
虚拟机模板: 在虚拟化环境中,可以创建虚拟机模板,包含了操作系统、软件和配置。当需要部署新的虚拟机时,只需从模板创建一个新的实例,确保每个实例都是相同的,而且不会因为手动修改而引入问题。
基础设施即代码(IaC): 使用工具如Terraform或AWS CloudFormation,可以将基础设施的配置描述为代码。这样,每次需要更改基础设施时,只需更新代码,然后通过运行脚本来创建新的基础设施,而不是在现有的基础设施上进行修改。
自动化部署流水线: 创建自动化的持续集成和持续部署(CI/CD)流水线,将代码、配置和基础设施的更新自动化地部署到目标环境。每次部署都会在干净的环境中创建新的实例,确保不会因为过去的状态而导致问题。
数据库镜像和快照: 在数据库领域,可以使用数据库镜像或快照来实现不可变性。当需要更新数据库时,首先创建一个数据库镜像或快照,然后在新的镜像或快照上进行修改和测试,最后切换到新的镜像或快照,确保不会影响生产数据。
云原生应用: 云原生应用本身就是采用了不可变基础设施的典型例子。通过将应用程序和其依赖项打包到容器中,每次部署都会使用新的容器镜像,确保应用程序在不同环境中保持一致。
2.5 服务网格化
Server Mesh,云原生服务网格是一种用于管理和监控在云原生环境中部署的微服务应用程序的工具集合。它提供了一种高度抽象和自动化的方式,以处理微服务之间的通信、流量管理、安全性和监控等方面的问题。服务网格的目标是使微服务应用程序更易于管理、扩展和维护,同时提供更好的可观察性和控制。

以下是云原生服务网格的一些关键概念和理解要点:
微服务通信管理: 在微服务架构中,服务之间的通信可能会变得复杂。服务网格通过为每个微服务注入代理(例如,Envoy或Linkerd),实现对通信的集中控制。这些代理负责处理服务之间的网络通信,提供负载均衡、超时、重试等功能。
流量管理: 服务网格允许你在微服务之间配置流量路由、拆分和重定向。这使得你可以在运行时实现 A/B 测试、金丝雀发布等策略,而无需修改应用程序代码。
安全性和认证: 服务网格提供了对服务之间通信的加密和认证支持。它可以管理服务之间的TLS(传输层安全协议)连接,并确保只有授权的服务能够进行通信。
监控和可观察性: 服务网格提供了强大的监控和追踪功能,以便实时了解服务的性能、延迟、错误等指标。这可以帮助你更好地理解应用程序的运行状况,快速诊断问题并做出优化。
策略和控制: 服务网格允许你定义策略,例如限制访问速率、重试次数和超时。这些策略可以在网格级别或服务级别进行配置,从而实现更好的控制和可靠性。
自动化: 通过使用服务网格,你可以将许多网络和通信方面的问题自动化。这减轻了开发人员的负担,使他们可以更专注于业务逻辑和应用程序开发。
多平台支持: 服务网格通常是跨多个云平台和容器编排系统(如Kubernetes)的,这使得你可以在不同环境中保持一致的管理和控制。
总之,云原生服务网格是一种帮助管理和控制云原生微服务应用程序的工具,通过处理通信、流量、安全性和监控等方面的问题,提供更好的可维护性、可观察性和控制性。
2.6 DevOps
一文搞懂DevOps:https://baijiahao.baidu.com/s?id=1686052246463497135&wfr=spider&for=pc
DevOps(Development和Operations的组合词)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。
它是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。

CI/CD
CI/CD是DevOps的核心实践,旨在实现频繁的代码集成和交付。
持续集成(Continuous Integration,CI)确保开发人员的代码变更定期地合并到共享存储库,并自动进行构建和测试。
持续交付(Continuous Delivery/Continuous Deployment,CD)则扩展了持续集成的概念,将自动化部署和交付过程引入,使得每次代码变更都可以快速、可靠地部署到生产环境。

GitLab:是一个自托管的Git项目仓库,同类产品还有GitHub、码云等。企业私有化推荐用GitLab,是因为它免费,GitHub收费。
Nexus:Nexus 是一个强大的Maven仓库管理器,它极大地简化了自己内部仓库的维护和外部仓库的访问。企业的网络环境通常不支持直接从公网仓库拉取Maven依赖,Nexus在此时就发挥了很大的作用。
Harbor:和Nexus类似,Harbor是Docker镜像仓库管理器,虽然Docker官方也提供了公共的镜像仓库,但是从安全和效率等方面考虑,部署私有环境内的Registry也是非常必要的。
Jenkins:Jenkins是一个开源的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件项目可以进行持续集成。DevOps各阶段的流水线配置,通常都通过 Jenkins 来执行。
Sonar:Sonar(SonarQube)是一个用于管理源代码质量的开源平台。Sonar 不只是一个质量数据报告工具,更是代码质量管理平台。
三、云原生的发展趋势
多云和混合云: 企业越来越倾向于使用多个云提供商的服务,以避免锁定和提高弹性。云原生技术在不同云平台之间提供了更大的可移植性和一致性,有助于实现多云和混合云架构。
边缘计算和边缘云原生: 随着边缘计算的兴起,边缘设备和边缘节点需要能够高效地运行和管理应用程序。云原生技术正在扩展到边缘环境,以支持边缘设备上的应用程序部署和管理。
Serverless和无服务器计算: 无服务器计算是云原生的一部分,它进一步推动了应用程序开发的自动化和简化。开发人员可以将注意力集中在代码编写上,而不必担心基础设施的管理。
AI和机器学习与云原生结合: 人工智能(AI)和机器学习(ML)在应用程序中的应用不断增加。将AI和ML与云原生结合,可以提供强大的基础设施支持,用于数据处理、模型训练和推理等。
持续演化和创新: 云原生领域仍在不断演化和创新。新的工具、平台和最佳实践不断涌现,以满足不断变化的需求和挑战。
更丰富的生态系统: 云原生技术生态系统将变得更加丰富多样。越来越多的厂商、开源项目和社区将会贡献和创新,以满足云原生的各种需求。
可观察性和安全性: 随着系统复杂性的增加,监控、日志、追踪和安全性变得更加重要。未来的云原生技术将会更加注重在应用程序和基础设施层面提供更好的可观察性和安全性。