
阿里巴巴 MySQL binlog 增量订阅&消费组件,主要用于MySQL和其他数据源的增量数据同步。
背景
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。基于日志增量订阅和消费的业务包括:
数据库镜像
数据库实时备份
索引构建和实时维护(拆分异构索引、倒排索引等)
业务 cache 刷新
带业务逻辑的增量数据处理
当前的 Canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
工作原理
Mysql的BinLog
BinLog记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间。主要用来备份和数据同步。binlog 有三种模式:STATEMENT、ROW、MIXED
STATEMENT 记录的是执行的sql语句
ROW 记录的是真实的行数据记录
MIXED 记录的是1+2,优先按照1的模式记录
update user set age=20
对应STATEMENT模式只有一条记录,对应ROW模式则有可能有成千上万条记录(取决数据库中的记录数)。
MySQL主备复制原理
简单说:
MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events;
MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log);
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据。
详细点:
Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master- info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。 当然这个过程本质上还是存在一定的延迟的。
binlog格式如下
mysql-bin.003831
mysql-bin.003840
mysql-bin.003849
mysql-bin.003858Canal工作原理
Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
为什么要用Canal
常见的数据同步方案:
Canal优点:
实时性高:Canal 可以实时解析数据库的二进制日志(binlog),捕获数据库变更操作,将变更内容及时传递给消费者,实现准实时的数据同步;
低侵入性:Canal 通过解析数据库的 binlog 实现数据捕获,不需要修改应用程序代码或数据库结构,对数据库的影响相对较小;
灵活的订阅机制:Canal 支持按照数据库、表、字段等多种粒度进行订阅,可以选择只订阅感兴趣的数据,避免传输不必要的数据;
支持多种数据库:Canal 最初是为 MySQL 设计的,但后来也支持了一些其他数据库(如 Oracle)的 binlog 解析,提供了跨数据库的数据同步能力;
数据解耦和同步:Canal 可以将数据库变更操作转化为特定格式的消息,然后通过消息中间件进行分发,实现数据的解耦和异步处理;
数据复制与分发:通过 Canal,可以将数据库的变更操作复制到不同的数据库实例,实现数据在不同环境之间的同步与分发;
灵活的消费方式:Canal 支持多种消费方式,可以通过 TCP、RabbitMQ、Kafka 等进行消费,根据实际需求选择最合适的方式;
丰富的监控和管理工具:Canal 提供了监控和管理工具,可以方便地查看订阅状态、消费延迟等信息,便于运维和故障排查。
安装和配置Canal
下面我们就开启mysql的主从同步机制,让Canal来模拟salvecanal.deployer-1.1.5.tar.gzcanal.admin-1.1.5.tar.gz
开启MySQL主从
Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。
开启binlog
查看binlog是否开启,未开启接着操作
show variables like '%log_bin%';
修改mysql配置文件:
vi /etc/my.cnf
添加内容:
log-bin=mysql-bin
server_id=1
binlog-do-db=ry-cloud配置解读:
log-bin=mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-bin
binlog-do-db=ry-cloud:指定对哪个database记录binary log events,这里记录ry-cloud这个库
server_id=1:指定当前服务的唯一标识
最终效果:
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
lower_case_table_names=1
query_cache_type=1
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow.log
long_query_time=0.01
log_output=FILE
log-bin=mysql-bin
server_id=1
binlog-do-db=ry-cloud重启mysql
systemctl restart mysqld
测试设置是否成功:在mysql控制台,或者Navicat中,输入命令:
show master status; #查看当前正在写入的binlog文件
show binary logs; #获取binlog文件列表
show binlog events; #只查看第一个binlog文件的内容
show binlog events in 'mysql-bin.000002';#查看指定binlog文件的内容修改任意表数据,利用mysqlbinlog工具测试:
#进入linux终端
#搜索你的mysqlbinlog工具
find / -name "mysqlbinlog"#查看日志明文
/usr/bin/mysqlbinlog -v --base64-output=decode-rows /var/lib/mysql/mysql-bin.000002设置用户权限
接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对ry-cloud这个库的操作权限。
create user canal@'%' IDENTIFIED by 'qweQWE123!@#';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'qweQWE123!@#';
FLUSH PRIVILEGES;安装Canal admin
https://github.com/alibaba/canal/releases/tag/canal-1.1.5上传解压
tar -zxvf canal.admin-1.1.5.tar.gz
配置文件
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: root
password: qweQWE123!@#
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
# canal-deployer连接admin的访问账号,这里密码为明文。canal-deployer中为密文
canal:
adminUser: admin
adminPasswd: 123456注意此处配置的mysql账号密码是否有crud权限,不是canal用户。记住此处的adminPasswd, 明文123456对应的密文是:
6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
配置数据库
建表
启动
降低启动内存
if [ -n "$str" ]; then
JAVA_OPTS="-server -Xms128m -Xmx512m"
else
JAVA_OPTS="-server -Xms128m -Xmx512m"
ficd /usr/local/src/canal-admin/bin
./startup.sh登录
http://linux:8089/默认密码:admin/123456
安装Canal
上传到linux
解压
tar -zxvf canal.deployer-1.1.5.tar.gz
编辑配置文件
vim conf/example/instance.properties
修改以下配置
注意:mysql地址自己灵活配置,以下假设mysql和Canal在一台机器上
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=qweQWE123!@#调小jvm内存
if [ -n "$str" ]; then
JAVA_OPTS="-server -Xms128m -Xmx512m -Xmn512m -XX:SurvivorRatio=2 -XX:PermSize=96m -XX:MaxPermSize=256m -Xss256k -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError"
else
JAVA_OPTS="-server -Xms128m -Xmx512m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxPermSize=128m "
fi独立启动
./startup.sh
集成Canal-admin启动
vi /usr/local/src/canal/conf/canal_local.properties注意修改ip,passwd,name
# register ip
canal.register.ip = 127.0.0.1
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
canal.admin.register.name = canal-01./startup.sh local #配合canal admin启动,用cannal_local.properties配置
Canal-admin查看注册情况
查看启动日志
tail -f ../logs/canal/canal.log
搞定。
Canal-admin配置实例
实例名字根据默认example取名,不能随意写
主要修改以下三个配置即可:
# 开启gtid,生成同步数据全局id,防止主从不一致
canal.instance.gtidon=true
# mysql连接用户名和密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=密码其他配置说明:
#################################################
# 同mysql集群配置中的serverId,mysql的server_id参数
# canal.instance.mysql.slaveId=0
# 开启gtid,生成同步数据全局id,防止主从不一致
canal.instance.gtidon=true
# binlog的pos位点信息,修改时重建实例,或删除实例配置文件。
canal.instance.master.address=10.2.55.55:3306
#mysql起始的binlog文件,默认最新数据
canal.instance.master.journal.name=
#mysql起始的binlog偏移量,只会在配置binlog文件中寻找
canal.instance.master.position=
#mysql起始的binlog时间戳,只会在配置binlog文件中寻找
canal.instance.master.timestamp=
#ysql起始的binlog的gtid,只会在配置binlog文件中寻找
canal.instance.master.gtid=
# 阿里云rds的sso配置
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# 开启tsdb功能,记录table mate变动
canal.instance.tsdb.enable=true
# tsdb数据存储在位置
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
# 备用数据库,当master数据库检查失败后,切换到该节点继续消费
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# mysql连接用户名和密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# 开启druid数据库密码加密
canal.instance.enableDruid=false
# 加密公钥
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# 匹配table表达式,需要处理的表
canal.instance.filter.regex=.*\\..*
# 匹配过滤table表达式,不需要处理的表
canal.instance.filter.black.regex=
# 匹配table字段表达式,指定传递字段,不指定全传。
#(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id
/name/contact/ch
# 匹配过滤table字段表达式,不传递的字段,canal.instance.filter.field为空时生效
@(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq消息配置
# mq topic
canal.mq.topic=example
# 动态topic配置,topic为表名
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
# mq分区
canal.mq.partition=0
# hash分区数量 ,为空默认为1个分区
#canal.mq.partitionsNum=3
# hash分区主键,没有冒号就使用表名进行分区。有冒号使用字段进行分区。
#canal.mq.partitionHash=test.table:id^name,.*\\..*保存 启动实例
启动实例 查看日志
查看日志 自习查看是否有异常,正常如下:
自习查看是否有异常,正常如下:
Canal服务模式
Canal目前支持四种服务模式,分别是:tcp, kafka, rocketMQ, rabbitMQ。我们就拿rabbitMQ和tcp做一下对比。
tcp/rabbitMQ优缺点
请注意,最终的选择应该根据你的具体需求、技术栈和系统架构来做出,权衡各种因素。
TCP-Spring Boot集成Canal(适合单机架构)
流程图
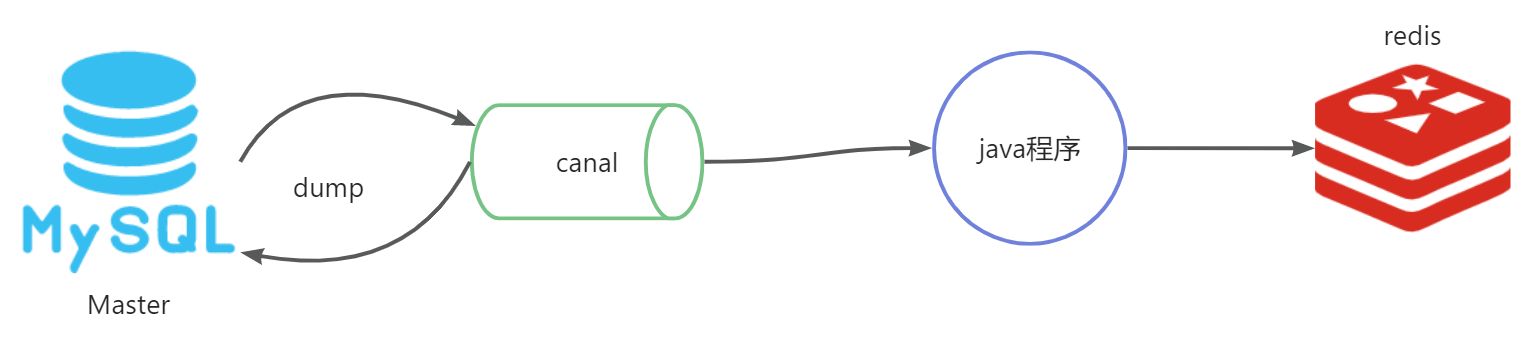
Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。方式一:我们可以利用Canal提供的Java客户端,监听Canal通知消息。当收到变化的消息时,完成对缓存的更新。地址:https://github.com/alibaba/canal/wiki/ClientExample方式二:不过这里我们会推荐使用GitHub上的第三方开源的canal-starter客户端。地址:https://github.com/NormanGyllenhaal/canal-client与SpringBoot完美整合,自动装配,比官方客户端要简单好用很多。
方式一
导入依赖
<!--canal.client的依赖-->
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.5</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.5</version>
</dependency>配置yml
canal:
host: linux
port: 11111
destination: example
username: canal
password: qweQWE123!@#
batch:
size: 100新建Canal客户端
package com.ruoyi.teaching.canal;
import com.alibaba.fastjson2.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
@Slf4j
@Component
public class CanalClient implements InitializingBean, DisposableBean {
@Value("${canal.host}")
private String canalHost;
@Value("${canal.port}")
private int canalPort;
@Value("${canal.destination}")
private String canalDestination;
@Value("${canal.username}")
private String canalUsername;
@Value("${canal.password}")
private String canalPassword;
@Value("${canal.batch.size}")
private int batchSize;
private static final Logger logger = LoggerFactory.getLogger(CanalClient.class);
private CanalConnector canalConnector;
private ExecutorService executorService;
@PostConstruct
public void canalConnector() {
this.canalConnector = CanalConnectors.newSingleConnector(
new InetSocketAddress(canalHost, canalPort),
canalDestination,
canalUsername,
canalPassword
);
}
@Override
public void afterPropertiesSet() throws Exception {
//初始化线程池
this.executorService = Executors.newSingleThreadExecutor();
//执行接收任务
this.executorService.execute(new Task());
}
@Override
public void destroy() throws Exception {
if (executorService != null) {
executorService.shutdown();
}
}
private class Task implements Runnable {
@Override
public void run() {
while (true) {
try {
//连接
canalConnector.connect();
//订阅
canalConnector.subscribe();
while (true) {
Message message = canalConnector.getWithoutAck(batchSize); // batchSize为每次获取的batchSize大小
long batchId = message.getId();
//获取批量的数量
int size = message.getEntries().size();
//如果没有数据
if (batchId == -1 || size == 0) {
// log.info("无数据");
try {
// 线程休眠2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
// 如果有数据,处理数据
printEntry(message.getEntries());
}
canalConnector.ack(batchId);
}
} catch (Exception e) {
logger.error("Error occurred when running Canal Client", e);
} finally {
canalConnector.disconnect();
}
}
}
}
private void printEntry(List<CanalEntry.Entry> entrys) {
for (CanalEntry.Entry entry : entrys) {
if (isTransactionEntry(entry)){
//开启/关闭事务的实体类型,跳过
continue;
}
//RowChange对象,包含了一行数据变化的所有特征
//比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等
CanalEntry.RowChange rowChage;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
}
//获取操作类型:insert/update/delete类型
CanalEntry.EventType eventType = rowChage.getEventType();
//打印Header信息
log.info("================》; binlog[{} : {}] , name[{}, {}] , eventType : {}",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType);
//判断是否是DDL语句
if (rowChage.getIsDdl()) {
log.info("================》;isDdl: true,sql:{}", rowChage.getSql());
}
System.out.println(rowChage.getSql());
//获取RowChange对象里的每一行数据,打印出来
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
//如果是删除语句
if (eventType == CanalEntry.EventType.DELETE) {
log.info(">>>>>>>>>> 删除 >>>>>>>>>>");
printColumnAndExecute(rowData.getBeforeColumnsList(), "DELETE");
//如果是新增语句
} else if (eventType == CanalEntry.EventType.INSERT) {
log.info(">>>>>>>>>> 新增 >>>>>>>>>>");
printColumnAndExecute(rowData.getAfterColumnsList(), "INSERT");
//如果是更新的语句
} else {
log.info(">>>>>>>>>> 更新 >>>>>>>>>>");
//变更前的数据
log.info("------->; before");
printColumnAndExecute(rowData.getBeforeColumnsList(), null);
//变更后的数据
log.info("------->; after");
printColumnAndExecute(rowData.getAfterColumnsList(), "UPDATE");
}
}
}
}
/**
* 执行数据同步
* @param columns
* @param type
*/
private void printColumnAndExecute(List<CanalEntry.Column> columns, String type) {
if(type == null){
return;
}
JSONObject jsonObject = new JSONObject();
for (CanalEntry.Column column : columns) {
jsonObject.put(column.getName(), column.getValue());
log.info("{}: {}", column.getName(), column.getValue());
}
// 此处使用json转对象的方式进行转换
// JSONObject.parseObject(jsonObject.toString(), xxx.class)
if(type.equals("INSERT")){
// 执行新增
log.info("新增成功->{}", jsonObject.toJSONString());
}else if (type.equals("UPDATE")){
// 执行编辑
log.info("编辑成功->{}", jsonObject.toJSONString());
}else if (type.equals("DELETE")){
// 执行删除
log.info("删除成功->{}", jsonObject.toJSONString());
}
}
/**
* 判断当前entry是否为事务日志
*/
private boolean isTransactionEntry(CanalEntry.Entry entry){
if(entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN){
log.info("********* 日志文件为:{}, 事务开始偏移量为:{}, 事件类型为type={}",
entry.getHeader().getLogfileName(),
entry.getHeader().getLogfileOffset(),
entry.getEntryType()
);
return true;
}else if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND){
log.info("********* 日志文件为:{}, 事务结束偏移量为:{}, 事件类型为type={}",
entry.getHeader().getLogfileName(),
entry.getHeader().getLogfileOffset(),
entry.getEntryType()
);
return true;
}else {
return false;
}
}
}启动测试数据库表中修改一条数据控制台监听修改如下:可以看到,Canal会将mysql所有的修改日志全部发送给java程序,我们只需要根据表名和操作类型去实现我们自己业务。
问题
数据解析是个体力活,能不能更简单一点?能!
方式二(推荐)
导入依赖
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>yml配置
canal:
destination: example # canal的集群名字,要与安装canal时设置的实例(instance)名称一致
server: linux:11111 # canal服务地址处理器
package com.ruoyi.teaching.canal;
import com.ruoyi.teaching.domain.TeachingPlan;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;
/*指定监听表名*/
@CanalTable("ya_teaching_plan")
@Component
public class TeachingPlanHandler implements EntryHandler<TeachingPlan> {
@Override
public void insert(TeachingPlan teachingPlan) {
System.out.println("新增业务");
}
@Override
public void update(TeachingPlan before, TeachingPlan after) {
System.out.println("更新业务");
}
@Override
public void delete(TeachingPlan teachingPlan) {
System.out.println("删除业务");
}
}rab bitMQ(适合分布式架构)
流程图
###
新建队列
新建交换机
名字为:exchange.fanout.canal类型为:topic
绑定队列
选中交换机,绑定队列queue.canal,routing key为example
编辑canal_local.properties
新增内容:
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
rabbitmq.host = ip
rabbitmq.virtual.host = canal
rabbitmq.exchange = exchange.fanout.canal
rabbitmq.username = canal
rabbitmq.password = canal
rabbitmq.deliveryMode = topic编辑实例
重启Canal
cd /usr/local/src/canal/bin
./stop.sh
./startup.sh local
tail -f ../logs/example/example.log测试
直接在navicate中修改mysql数据去队列中获取消息查看内容后续就可以使用Spring AMQP在spring boot中获取队列中的消息处理业务了。